In debates over the future of artificial intelligence, many experts think of these machine-based systems as coldly logical and objectively rational. But in a new study, Princeton University-based researchers have demonstrated how machines can be reflections of their creators in potentially problematic ways.
Common machine-learning programs trained with ordinary human language available online can acquire the cultural biases embedded in the patterns of wording, the researchers reported in the journal Science April 14. These biases range from the morally neutral, such as a preference for flowers over insects, to discriminatory views on race and gender.
Identifying and addressing possible biases in machine learning will be critically important as we increasingly turn to computers for processing the natural language humans use to communicate, as in online text searches, image categorization and automated translations.
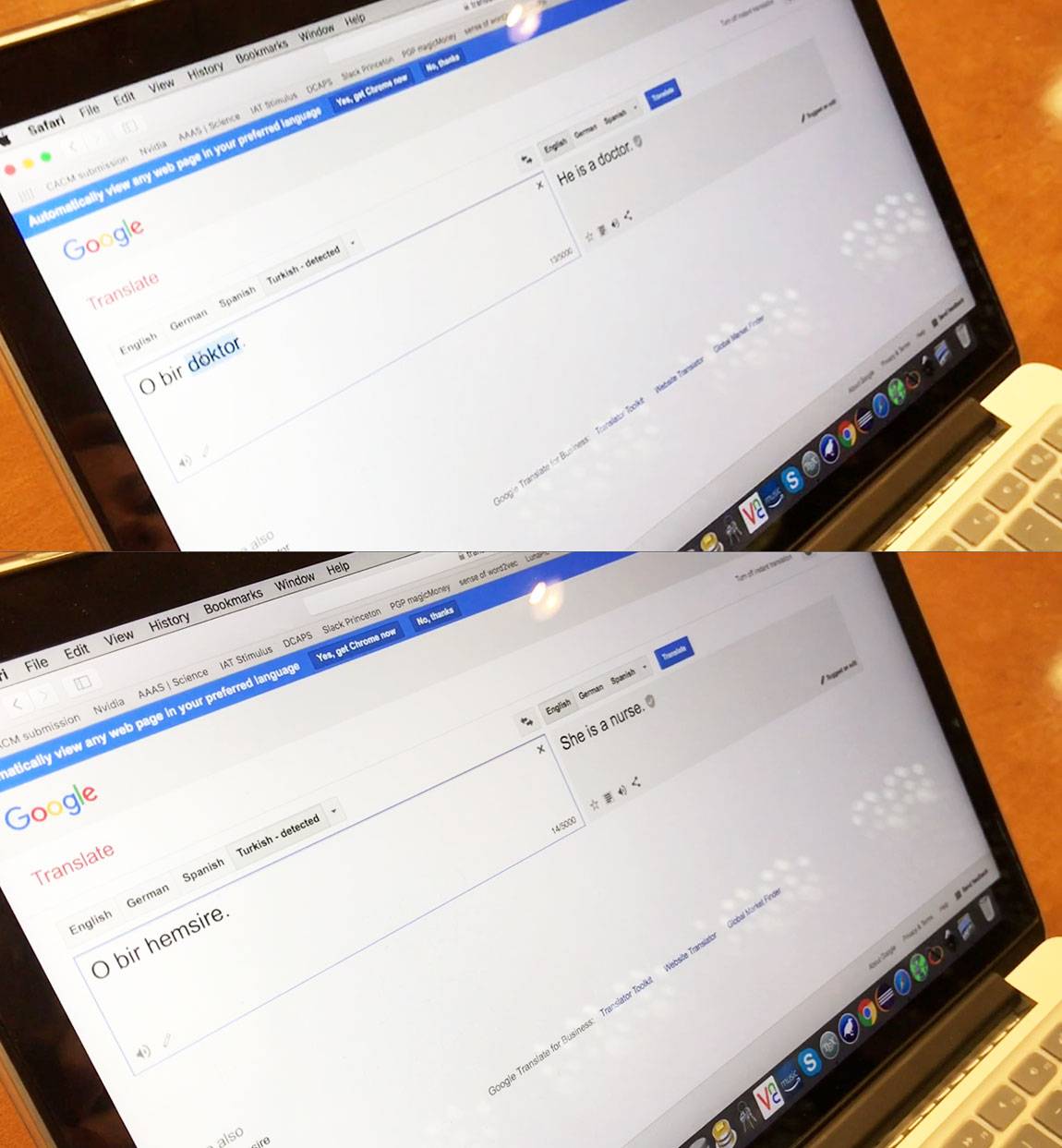
Princeton University-based researchers have found that machine-learning programs can acquire the cultural biases embedded in the patterns of wording, from a mere preference for flowers over insects, to discriminatory views on race and gender. For example, machine-learning programs can translate foreign languages into gender-stereotyped sentences. Turkish uses the gender-neutral pronoun, "o." Yet, when the Turkish sentences "o bir doktor" (top) and "o bir hemşire" (bottom) are entered into Google Translate, they translate into English as "he is a doctor" and "she is a nurse." (Images by the Office of Engineering Communications)
"Questions about fairness and bias in machine learning are tremendously important for our society," said co-author Arvind Narayanan, a Princeton University assistant professor of computer science and the Center for Information Technology Policy (CITP), as well as an affiliate scholar at Stanford Law School's Center for Internet and Society.
Narayanan worked with first author Aylin Caliskan, a Princeton postdoctoral research associate and CITP fellow, and Joanna Bryson, a reader at the University of Bath and CITP affiliate.
"We have a situation where these artificial-intelligence systems may be perpetuating historical patterns of bias that we might find socially unacceptable and which we might be trying to move away from," Narayanan said.
As a touchstone for documented human biases, the researchers turned to the Implicit Association Test used in numerous social-psychology studies since its development at the University of Washington in the late 1990s. The test measures response times in milliseconds by human subjects asked to pair word concepts displayed on a computer screen. The test has repeatedly shown that response times are far shorter when subjects are asked to pair two concepts they find similar, versus two concepts they find dissimilar.
For instance, words such as "rose" and "daisy," or "ant" and "moth," can be paired with pleasant concepts such as "caress" and "love," or unpleasant ones such as "filth" and "ugly." People more associate the flower words with pleasant concepts more quickly than with unpleasant ones; similarly, they associate insect terms most quickly with unpleasant ideas.
The Princeton team devised an experiment with a program called GloVe that essentially functioned like a machine-learning version of the Implicit Association Test. Developed by Stanford University researchers, the popular open-source program is of the sort that a startup machine-learning company might use at the heart of its product. The GloVe algorithm can represent the co-occurrence statistics of words in, say, a 10-word window of text. Words that often appear near one another have a stronger association than those words that seldom do.
The Stanford researchers turned GloVe loose on a huge trove of content from the World Wide Web containing 840 billion words. With in this store of words, Narayanan and colleagues examined sets of target words, such as "programmer, engineer, scientist" and "nurse, teacher, librarian," alongside two sets of attribute words such as "man, male" and "woman, female," looking for evidence of the kinds of biases humans can possess.
In the results, innocent, inoffensive preferences, such as for flowers over insects, showed up, but so did more serious prejudices related to gender and race. The Princeton machine-learning experiment replicated the broad biases exhibited by human subjects who have taken select Implicit Association Test studies.
For instance, the machine-learning program associated female names more than male names with familial attributes such as "parents" and "wedding." Male names had stronger associations with career-related words such as "professional" and "salary." Of course, results such as these are often just objective reflections of the true, unequal distributions of occupation types with respect to gender — like how 77 percent of computer programmers are male, according to the U.S. Bureau of Labor Statistics.
This bias about occupations can end up having pernicious, sexist effects. For example, machine-learning programs can translate foreign languages into sentences that reflect or reinforce gender stereotypes. Turkish uses a gender-neutral, third person pronoun, "o." Plugged into the online translation service Google Translate, however, the Turkish sentences "o bir doktor" and "o bir hemşire" are translated into English as "he is a doctor" and "she is a nurse."
"This paper reiterates the important point that machine-learning methods are not 'objective' or 'unbiased' just because they rely on mathematics and algorithms," said Hanna Wallach, a senior researcher at Microsoft Research New York City, who is familiar with the study but was not involved in it. "Rather, as long as they are trained using data from society, and as long as society exhibits biases, these methods will likely reproduce these biases."
The researchers also found that machine-learning programs more often associated African American names with unpleasantness than European American names. Again, this bias plays out in people. A well-known 2004 paper by Marianne Bertrand from the University of Chicago and Sendhil Mullainathan of Harvard University sent out close to 5,000 identical resumes to 1,300 job advertisements, changing only the applicants' names to be either traditionally European American or African American. The former group was 50 percent more likely to be offered an interview than the latter.
Computer programmers might hope to prevent the perpetuation of cultural stereotypes through the development of explicit, mathematics-based instructions for the machine learning programs underlying AI systems. Not unlike how parents and mentors try to instill concepts of fairness and equality in children and students, coders could endeavor to make machines reflect the better angels of human nature.
"The biases that we studied in the paper are easy to overlook when designers are creating systems," Narayanan said. "The biases and stereotypes in our society reflected in our language are complex and longstanding. Rather than trying to sanitize or eliminate them, we should treat biases as part of the language and establish an explicit way in machine learning of determining what we consider acceptable and unacceptable."
The paper, "Semantics derived automatically from language corpora contain human-like biases," was published April 14 in Science.





