Welcome to the home page of Prof. Naomi Ehrich Leonard’s Research Group.

Opinion dynamics allow robotic networks to make complex decisions and avoid deadlock 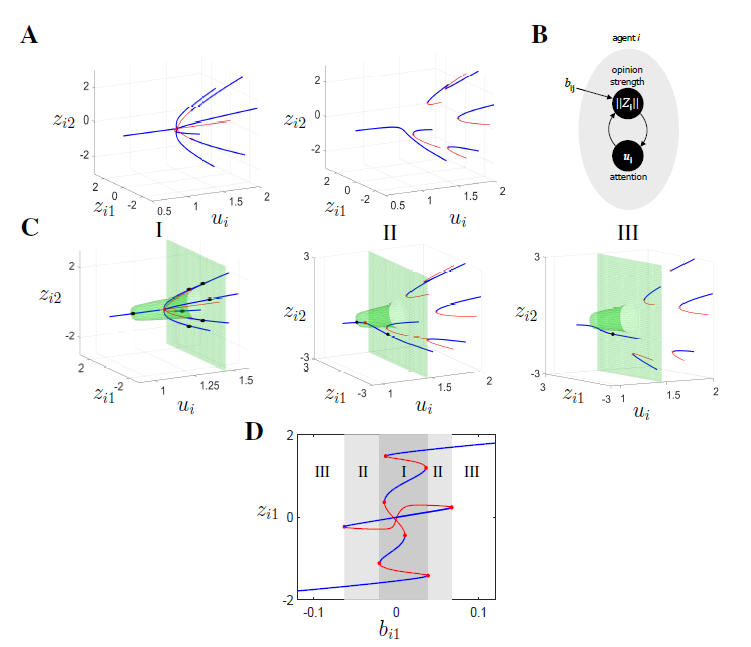
Bifurcation diagram of single agent opinion dynamics with respect to the attention parameter 
Desert ants’ survival strategy emerges from millions of simple interactions 
Improvised dance embodies complexities of social decisions 
“Rhythm bots” is a work at the intersection of human-robot interaction, multi-robot dynamics, and art 
Leonard Lab group photo, May 2022!
Listen to Naomi Leonard’s interview with Alberto Padoan for the inControl podcast
Part I: Geometric Control on Lie Groups, Underwater Vehicles and Collective Motion, Coordination in Animal Groups, Decision Making in Honeybees and Bifurcation Theory. Listen here.
Part II: Unveiling the Dynamics of Collective Decision-Making from Flocking Starlings to Desert Ants, Political Polarization, and the Creative Dance Between Arts and Control Theory. Listen here.
News
- Part I and Part II of Naomi Leonard’s interview for inControl podcast are now available
- New review paper Fast and Flexible Multiagent Decision-Making now available
- Naomi Leonard gives plenary lecture “Fast and Flexible Multi-Agent Decision-Making” at 2023 IEEE Conference on Decision and Control (CDC)
- Rhythm Bots in the Forum, Lewis Arts Complex, Friday May 12, 4-7 pm, free and open to the public. See this playlist of videos on Rhythm Bots from May 2022, courtesy of CreativeX
- Giovanna Amorim awarded a Martin Summerfield Second Year Fellowship from the MAE Department
- Anthony Savas gave his final public oral for his PhD thesis on September 2, 2022. His PhD thesis is here
- Anastasia Bizyeva gave her final public oral for her PhD thesis on August 30, 2022. Her PhD thesis is here
- Naomi Ehrich Leonard selected as recipient of the 2023 IEEE Control Systems Award “for contributions to applications and theory for control of nonlinear and multiagent systems”. Read about the award and past recipients.
- Shinkyu Park and Naomi Ehrich Leonard win the 2022 O. Hugo Schuck Award for Best Paper at the 2021 American Control Conference for their paper “KL Divergence Regularized Learning Model for Multi-Agent Decision Making”
- Mari Kawakatsu gave her final public oral for her PhD thesis on June 10, 2022. Her PhD thesis is here
- Udaya Ghai, Udari Madhushani, Naomi Leonard, and Elad Hazan awarded “Best Poster at the 2022 ICLR Workshop on Gamification and Multiagent Solutions”
- Rhythm Bots, a new kinetic sculpture of synchronously moving robots, exhibited at Pink Noise Projects, 319 N 11th Street, 2L, Philadelphia. Opening: May 6, 6-9 pm; Saturdays and Sundays, May 7-29, 2-6 pm. Special hours for Robotics+Art at ICRA’22, May 23, 4-6pm; May 24, 5-7pm; May 25, 12-2pm
- Justin Lidard awarded an NSF Graduate Research Fellowship!
- Charlotte Cathcart wins SEAS Excellence in Teaching Award for her Fall ’21 AI work in MAE 223: Modern Solid Mechanics!
- Leonard Lab contributes to PNAS special issue on political polarization — New York Times op ed and news story on Princeton’s webpage
- Anastasia Bizyaeva wins Award for Excellence from Princeton SEAS
- Udari Madhushani awarded the Harold W. Dodds Fellowship, a Princeton Graduate Honorific, for 2021-22
- Justin Lidard awarded a Martin Summerfield Second Year Fellowship from the MAE Department, selected as one of Aviation Week’s 20 Twenties winners for 2021
- Naomi Leonard gives TEDx talk on Flock Logic: How Groups Move in Nature, by Design, and on Stage on March 4, 2021
- STC 209: Transformations in Engineering and the Arts goes on-line for Spring 2021
- Congratulations to Shinkyu Park on starting as Assistant Professor at KAUST in January 2021
- Desmond Zhong gave his final public oral for his PhD thesis on September 30, 2020. His PhD thesis is here.
- Justin Lidard awarded an NDSEG Graduate Fellowship
- Desmond Zhong awarded the Britt and Eli Harari Fellowship 2019-2020 from MAE.
- Anastasia Bizyaeva and Udari Madhushani awarded the Larisse Rosentweig Klein Memorial Award (MAE) 2019-2020 from MAE
- Bec Gray gave her final public oral for her PhD thesis on July 19, 2019. Her PhD thesis is here.
- Renato Pagliara gave his final public oral for his PhD thesis on July 18, 2019. His PhD thesis is here.
- Udari Madhushani wins President’s Award for Scientific Research from the National Research Council of Sri Lanka
- Liz Davison gave her final public oral for her PhD thesis on May 17, 2019. Her PhD thesis is here.
- Anastasia Bizyaeva awarded an NSF Graduate Fellowship
- Peter Landgren gave his final public oral for his PhD thesis on November 9, 2018. His PhD thesis is here.∂
- Anastasia Bizyaeva awarded Phillips Second Year Fellowship from the MAE Department for 2018-2019
- Udari Madhushani awarded the Elliotte Robinson Little ’25 Student Aid Fund Fellowship (Graduate School), Summerfield Second Year Fellowship (MAE) for 2018-2019, and the Athena-Feron Prize (MAE) for achievement in Mathematics
- Naomi Leonard delivered the Hendrik W. Bode Prize Lecture at the IEEE Conference on Decision and Control, Melbourne, Australia, December 15, 2017. Video is here
- Anthony Savas awarded an NDSEG graduate fellowship starting September 2017.
- Will Scott gave his final public oral for his PhD thesis on December 16, 2016. His PhD thesis is here.
- Katie Fitch gave her final public oral for her PhD thesis on September 23, 2016. Her PhD thesis is here.
- Vaibhav Srivastava joined the faculty of the Electrical and Computer Engineering Department at Michigan State University
- Anthony Savas awarded a Phillips Second Year Fellowship from the MAE Department for 2016-2017 for excellence in both course work and research and the Athena-Feron Prize for achievement in mathematics.
- Desmond Zhong awarded the inaugural MAE department Second Year Fellowship for 2016-2017 for excellence in both course work and research.
- Liz Davison was awarded an NSF Graduate Fellowship.
- Renato Pagliara was awarded a Phillips Second Year Fellowship for 2015-2016, which recognizes a second-year MAE graduate student who has demonstrated excellence in both course work and research.
- Katie Fitch was awarded the Larisse Rosentweig Klein Memorial Award from the MAE Department for 2015-2016 for outstanding promise in graduate research.
- Katie Fitch was awarded a Wu Prize for 2015-2016 from the Princeton School of Engineering and Applied Science for performance at the highest level as a scholar and researcher.
- Peter Landgren awarded an NDSEG graduate fellowship starting September 2015.
- Tian Shen gave her final public oral for PhD thesis on December 9, 2014. Her PhD thesis is here.
- Will Scott awarded the 2014 Crocco Award for Teaching Excellence by the Faculty of the MAE Department in recognition of outstanding performance as an Assistant in Instruction for MAE 434 (Modern Control) in Fall 2013.
- Paul Reverdy gave his final public oral for PhD thesis on September 3, 2014. His PhD thesis is here.
- Best student paper awarded to Paul Reverdy at the 2014 European Control Conference in Strasbourg, France for the paper:
Contact
Professor Naomi Ehrich Leonard
Edwin S. Wilsey Professor of Mechanical and Aerospace Engineering
Director, Princeton University Council on Science and Technology
Editor, Annual Review of Control, Robotics, and Autonomous Systems
MAE Faculty Webpage
Email: naomi@princeton.edu
Phone: (609) 258-5129
Office: D-234 Engineering Quadrangle, Olden St., Princeton, NJ 08544
Web Admins
Jeffrey Addo
Email: jaddo@princeton.edu
Justin Lidard
Email: jlidard@princeton.edu
María Santos
Email: maria.santos@princeton.edu
Ian Xul Belaustegui
Email: ianxul@princeton.edu