My research focuses on the neuroscience of reinforcement
learning (RL). My methods are computational modeling,
behavioral psychophysics, pupillometry, EEG and fMRI
and my goal is to use these methods to pick apart the
algorithms underlying behavior.
My work splits into three separate projects each probing
a different aspect of RL: the
learning rate,
the
state space and the
explore-exploit dilemma.
How fast should we learn?
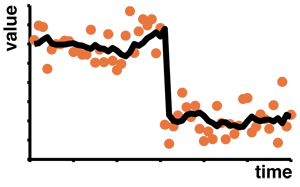 This work looks at the rate at which learning occurs.
Traditionally this `learning rate' is assumed to
be constant over time, but in many cases a constant
learning rate is suboptimal, suggesting that
performance could be improved if the learning rate
can change.
This project seeks to test whether the learning rate
does indeed vary over time and investigate the
neural and computational factors that determine its
setting.
This work looks at the rate at which learning occurs.
Traditionally this `learning rate' is assumed to
be constant over time, but in many cases a constant
learning rate is suboptimal, suggesting that
performance could be improved if the learning rate
can change.
This project seeks to test whether the learning rate
does indeed vary over time and investigate the
neural and computational factors that determine its
setting.
Representative publications:
Wilson, R. C., Nassar, M. R., & Gold, J. I. (2013).
A Delta-rule approximation to Bayesian inference in change-point problems.
PLOS Computational Biology, 9(7), e1003150
[pdf]
[supplement]
Nassar, M. R., Rumsey, K. M., Wilson, R. C., Parikh,
K., Heasly, B., & Gold, J. I. (2012).
Rational regulation of learning dynamics by pupil-linked arousal systems.
Nature Neuroscience, 15, 1040-1046. doi:10.1038/nn.3130
[pdf]
Wilson, R. C., Nassar, M. R., & Gold, J. I. (2010).
Bayesian online learning of the hazard rate in
change-point problems.
Neural Computation, 22(9), 2452-2476
[pdf]
[code]
Nassar, M. R., Wilson, R. C., Heasly, B., & Gold, J. I. (2010).
An approximately Bayesian Delta-rule model explains the dynamics of belief updating in a changing environment.
Journal of Neuroscience, 30(37), 12366-12378
[pdf]
Learning and representing the state space
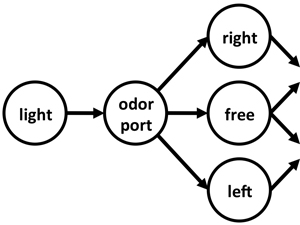 At the heart of all RL models is the concept of a state
space -- an abstract representation of a task that
describes its underlying structure. In most models of
behavior, it is assumed that animals know the state space
before learning begins, as if all tasks come with an
`instruction set'. In the real world this is clearly
not true and the state space must be learned. This
project asks: How the is state space is learned? and
Where are the states represented?
At the heart of all RL models is the concept of a state
space -- an abstract representation of a task that
describes its underlying structure. In most models of
behavior, it is assumed that animals know the state space
before learning begins, as if all tasks come with an
`instruction set'. In the real world this is clearly
not true and the state space must be learned. This
project asks: How the is state space is learned? and
Where are the states represented?
Representative publications:
Wilson, R. C., Takahashi, Y. K., Schoenbaum, G., & Niv, Y. (accepted).
Orbitofrontal cortex as a cognitive map of task space.
Neuron
Wilson, R. C., & Niv, Y. (2012).
Inferring relevance in a changing world.
Frontiers in Human Neuroscience, 5:189. doi: 10.3389/fnhum.2011.00189
[pdf]
The explore-exploit dilemma
 When you go to your favorite restaurant do you order
the same thing as usual, a dish you are sure to find
tasty but that yields no information, or do you try
one of the specials and learn something new? This
simple conundrum, deciding
between going with what you know or trying something
different, is at the heart of the exploration-exploitation
dilemma and whether it's a cow looking for greener grass
or a human looking for love, this problem is
ubiquitous and important to solve. This work probes
the neural mechanisms underlying the explore-exploit
tradeoff in humans.
When you go to your favorite restaurant do you order
the same thing as usual, a dish you are sure to find
tasty but that yields no information, or do you try
one of the specials and learn something new? This
simple conundrum, deciding
between going with what you know or trying something
different, is at the heart of the exploration-exploitation
dilemma and whether it's a cow looking for greener grass
or a human looking for love, this problem is
ubiquitous and important to solve. This work probes
the neural mechanisms underlying the explore-exploit
tradeoff in humans.
Representative publications:
Wilson, R. C., Geana, A., White, J. M., Ludvig, E. A.
& Cohen, J. D. (2013).
Exploration strategies in human decision making.
Reinforcement Learning & Decision Making
[pdf]
Geana, A., Wilson, R. C., & Cohen, J. D. (2013).
Reward, Risk & Ambiguity in Human Exploration:
A Wheel of Fortune Task.
Reinforcement Learning & Decision Making
[pdf]
Reverdy, P., Wilson, R. C., Holmes, P., & Leonard, N. E. (2012).
Towards optimization of a human-inspired heuristic for solving
explore-exploit problems.
51st IEEE Conference on Decision & Control (pp. 2820-2825)
[pdf]